データ分析とは、物事を判断するために必要な情報を集め、整理・分類・分解し比較することで意味合いを読み取り評価するプロセスを指します。データ分析を行うことで、過去のデータ(事実を表すデータ)から知見を得ることができます。
統計量を算出することやグラフなどで可視化する作業をデータ分析と考える人もいらっしゃるかもしれませんが、それを行うことだけが分析ではありません。仮説を立て考察することを含めたプロセス全体がデータ分析です。
データ分析の目的は、データ(根拠)に基づいた判断を行うことです。過去(現在も含め)のデータを実際におきている事象やあるべき姿と照らし合わせ、そのギャップを課題として 抽出し、課題の背景となる原因の仮説を 立てて改善策を検討することが必要です。
感覚や主観による考察を行うと、先入観やステレオタイプに陥る可能性が高くなります。一方でデータ分析を行うことで、定量的かつ客観的な視点で課題を認識することができるため、より適切な課題認識ができるようになります。
感覚や主観によって意思決定をしようとすると、曖昧な判断基準によって思考や議論が発散しがちです。一方、データ分析に基づく意思決定では、シーン毎に確認すべき観点や判断基準を設けることができます。スピーディーに意思決定を行い、関係者に根拠を示すことでビジネスを迅速に進めることが可能となります。
データ分析により課題を抽出すれば、どの点を改善することでどこがどれだけ改善できるか等の定量的な仮説を検討することができます。
データ分析を活用し仮説に沿った予測を立てることによって将来予測の精度も高まります。

《 7つの業務課題とデータ分析 》
7つの業務課題をテーマにデータ分析の分析例をご紹介するPDF資料がダウンロードできます。顧客獲得や不正検知、歩留改善、需要予測など、さまざまな業務でデータ分析はどう行うのか?の例をご紹介していますので、データ分析業務の推進のヒントにご活用ください。
データ可視化とは、データビジュアライゼーションとも呼ばれ、一般的にはグラフやチャートを用いた数値の視覚化を指します。
可視化の手法は数多くありますが、例えば、折れ線グラフ、円グラフ、棒グラフのようなシンプルなグラフや、バブルチャート、ヒートマップ、地図を使用したチャート等も使用されます。データ可視化は、データ分析の序盤では、そのデータを理解するために用いられ、終盤では分析結果を分かりやすく関係者に伝えるために用いることができます。
図:データ可視化のグラフ例
分析モデルという言葉は、分析手法を指す言葉の代用として用いられる場合もありますが、ここではデータ可視化に続く分析の工程としての分析モデル化について説明します。分析モデル化(またはモデリング)は、数学(統計)に基づくルールやアルゴリズムを用いて計算・解析を行ってデータを構造化することを指し、そこで構造化された結果を分析モデルと呼びます。
また、過去のデータ群を基にアルゴリズムに基づいたコンピューターの自動計算でモデルを生成することから、そのプロセスを機械学習とも呼びます。分析モデルは一般的に、数式やチャートで可視化できますが、モダンな手法の場合、複雑で簡単には可視化できない手法も存在します。
《 7つの業務課題とデータ分析 》
7つの業務課題をテーマにデータ分析の分析例をご紹介するPDF資料がダウンロードできます。顧客獲得や不正検知、歩留改善、需要予測など、さまざまな業務でデータ分析はどう行うのか?の例をご紹介していますので、データ分析業務の推進のヒントにご活用ください。
クロス集計は、通常の業務でも日常的に作成しています。例えば「商品別×月別の売上高」のような表を作成する場合、クロス集計表を作成します。ただし、データ分析でのクロス集計は数値の集計を行うやり方と違って、カテゴリ値の出現数を数える(度数)ことに使用されるのが普通です。二つの性質を縦横に表した度数のクロス集計は、その性質間の関係性を可視化するツールとして使用できます。
例えば、縦に原因の候補、横に結果となるようにカテゴリ値を配置し度数を表すと、原因の候補が結果に相関するかを分析できます。
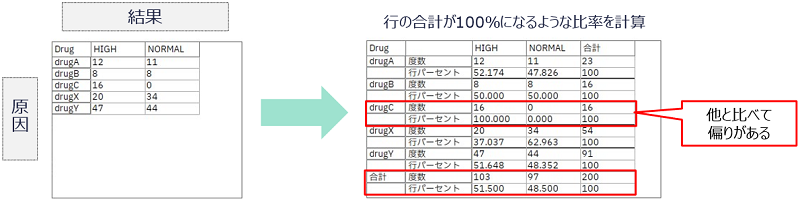
図:クロス修正の例
散布図は、2つの数値を表すデータを縦横にとったチャートです。
レコード毎に2つの値の交点に点をプロットすることで二つの値の間にある関係を可視化するツールとして使用できます。
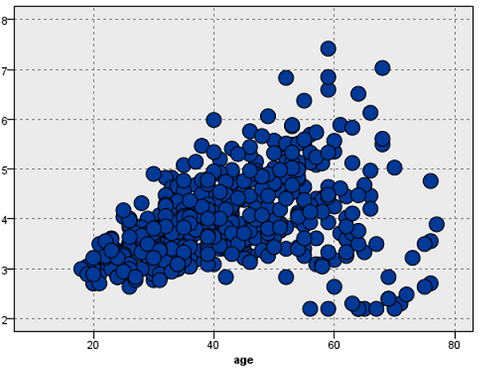
図:散布図の例
ある結果に対する原因を想定して、その関係性をモデル化するのが回帰分析です。
一般的には、ある結果(目的変数)に対する原因(説明変数)がひとつの場合を単回帰、複数の場合を重回帰と呼びます。
また、回帰には直線的な方程式で表すことができる線形回帰とそうでない非線形の分析モデルが存在します。
例えば、線形の単回帰の場合、以下のようなイメージとなります。
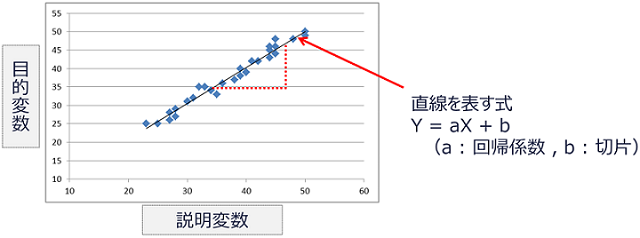
図:回帰分析の例
《 7つの業務課題とデータ分析 》
7つの業務課題をテーマにデータ分析の分析例をご紹介するPDF資料がダウンロードできます。顧客獲得や不正検知、歩留改善、需要予測など、さまざまな業務でデータ分析はどう行うのか?の例をご紹介していますので、データ分析業務の推進のヒントにご活用ください。
データの集まりの中で複数の性質(値の偏り等)を元に いくつかのグループに分類する手法を指します。あらかじめ決められた分類に属している個々の値がどうか?の分析ではなく、あくまで値を基にして似通った性質の集団を見つけることがクラスター分析の目的となります。
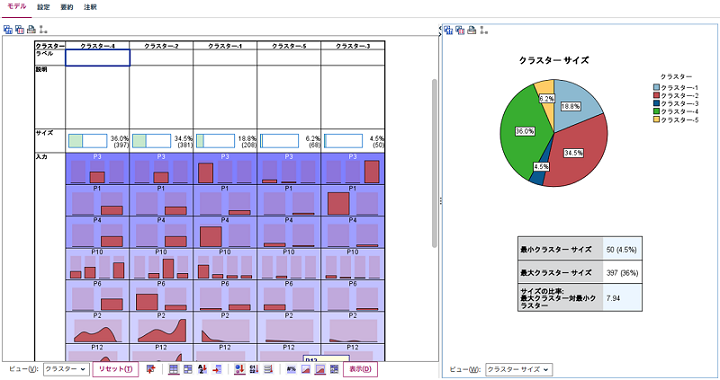
図:クラスター分析の例
デシジョンツリーは、決定木とも呼ばれる分析モデル化手法です。1つの目的変数に対して複数の説明変数を与えて、手法で定められた基準に従って、説明変数の値でデータ群を分割していくことで分類のルールを形成していきます。
形成されたルールは、木構造(ツリー構造)で視覚化できるため、データ分析に詳しくない人でも、直観的に理解できるというメリットがあります。
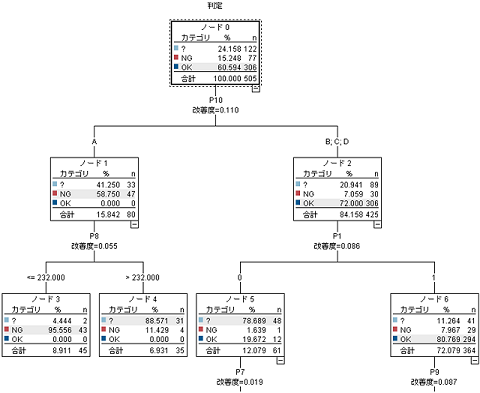
図:デシジョンツリーのモデル例
機械学習によるモデル化の手法であり 、単一の分析モデルで表さず、複数の分析モデルの組み合わせや集合体を構成し、より精度の高いモデルを構築する方法を総称してアンサンブル学習と呼びます。
《 7つの業務課題とデータ分析 》
7つの業務課題をテーマにデータ分析の分析例をご紹介するPDF資料がダウンロードできます。顧客獲得や不正検知、歩留改善、需要予測など、さまざまな業務でデータ分析はどう行うのか?の例をご紹介していますので、データ分析業務の推進のヒントにご活用ください。
分析に必要なデータを集めますが、1か所(1システム)内に必要な全てのデータが揃っているとは限りません。
複数のシステムからデータを集めて分析するためには、データ間に存在する仕様の相違点(例えば同じ事柄を表すコード体系が違う。記録する基準日や記録間隔が異なる。等)を解消する必要があります。
相違点を解消し結合させるためには、データを集計や変換、除去する等の加工が必要です。また、システムで管理されていないローカルデータの場合、空欄や異常値などの無効値が含まれていて補正が必要な場合もあります。
取り扱うデータが手に入ったら、どのような性質をもったデータなのかを理解するために、統計量を計算・可視化して確認することが必要です。
・値の取りうる範囲や偏りに傾向があるか?
・目的変数(事象の結果となる項目)に相関の高い項目はどれか?
可視化によって多くの気づきを得ることができます。
データ分析の目的や仮説に応じて、分析手法を選択し分析モデルを構築します。
・性質の似通ったグループに分ける → クラスター分析
・目的変数=数値を予測する → 回帰
・目的変数=カテゴリ値(OK/NG等)を予測 → クラシフィケーション(※1)
実際は、それぞれに対して様々な手法が存在します。
また、予測を目的とした分析モデル化手法を使用すると、重要な(相関の高い)説明変数を理解することができるため、分析モデルを読み解くことで、課題解決のための施策を考察することにも繋がります。
なお、分析モデル化の作業工程は、手計算で進められる計算量ではありませんので、分析ツールを用いるのが一般的です。
(※1)クラシフィケーション(または、クラス分類)とは、回帰の対義となる予測手法です。
あらかじめ定義されたカテゴリ値(=クラス)のどれに相当するかを予測する手法の総称であり、クラスター分析とは目的が異なります。
《 7つの業務課題とデータ分析 》
7つの業務課題をテーマにデータ分析の分析例をご紹介するPDF資料がダウンロードできます。顧客獲得や不正検知、歩留改善、需要予測など、さまざまな業務でデータ分析はどう行うのか?の例をご紹介していますので、データ分析業務の推進のヒントにご活用ください。
一般的に、データ可視化やデータモデル化をサポートまたは自動で実行することができる、コンピューターソフトウェアを総称してデータ分析ツールと呼びます。
一般的なツールでは、データ可視化機能として、あらかじめ用意されたグラフ・チャート作図手法に対して、入力となる値を選択することで、表示結果を出力する機能を持ちます。また、合計や平均、標準偏差、相関係数などの各種統計量の算出を行う機能を持っているのが一般的です。
更に高度なデータ分析機能を有するツールでは、機械学習による分析モデル化アルゴリズムを搭載しているツールも有ります。
なお、データ分析の全体プロセスの中で、実は一番工数を費やすのがデータ準備です。
素性の異なる複数のデータをブレンドして分析可能な状態にするには、データ加工ツールが別途で必要になる場合があります。一部のデータ分析ツールではデータ準備に必要な機能も搭載し、全てのワークロードを1つのソフトウェア上で遂行することができます。
前のセクションでも触れましたが、データ分析の全ワークロードで最も工数を費やすのがデータ準備工程です。
また、簡易なデータ分析ツールでは、記述統計量の算出やデータ可視化はできても、機械学習によるモデル化は搭載していない(または数種の限定的な手法しか搭載していない)場合があります。
当社がおすすめするデータ分析ツールは、uniSQUARE MLです。
uniSQUARE MLは、データ準備からデータ可視化、機械学習によるデータ分析モデルの構築まで、すべての分析ワークロードに対応したワークベンチです。実装した分析手順は、ストリームと呼ばれるフロー図に表わされ、複数の分析担当者の間で共有する際にも理解しやすく、再利用も容易です。
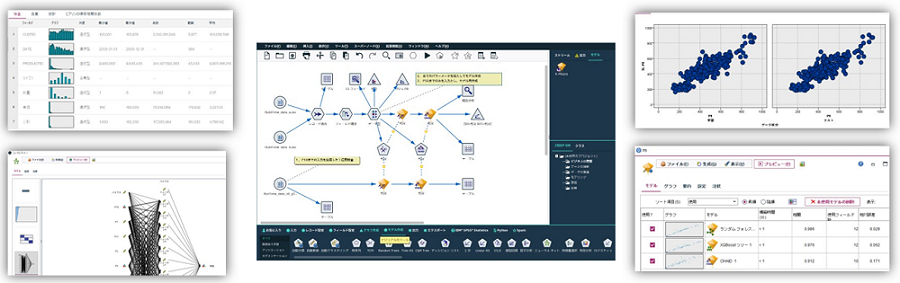
※uniSQUARE MLは、IBM SPSS ModelerのOEM製品であり、同様の機能を有しています。
《 7つの業務課題とデータ分析 》
7つの業務課題をテーマにデータ分析の分析例をご紹介するPDF資料がダウンロードできます。顧客獲得や不正検知、歩留改善、需要予測など、さまざまな業務でデータ分析はどう行うのか?の例をご紹介していますので、データ分析業務の推進のヒントにご活用ください。
《 7つの業務課題とデータ分析 》
7つの業務課題をテーマにデータ分析の分析例をご紹介するPDF資料がダウンロードできます。顧客獲得や不正検知、歩留改善、需要予測など、さまざまな業務でデータ分析はどう行うのか?の例をご紹介していますので、データ分析業務の推進のヒントにご活用ください。


おすすめソリューション
