歩留まり改善/予防・予知保全のための
「予兆検知ソリューション」
「予兆検知ソリューション」では、製造データを活用し統計解析や機械学習によって、お客様の製造ラインにあった「予兆検知モデル」を構築します。さらに、刻々と生成される製造データを「予兆検知モデル」でリアルタイムに監視し、問題発生が予測されると担当者に通知を発信します。予測による通知を受け取ることにより事前対策を講じることが可能となります。
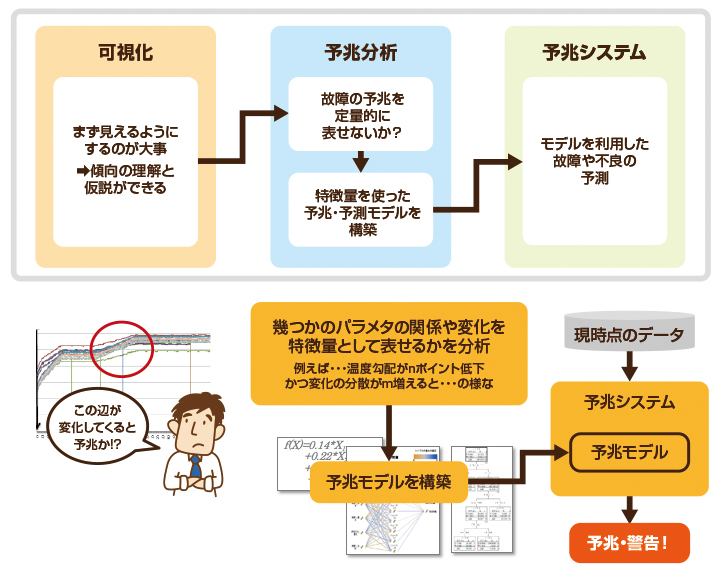
「予兆検知ソリューション」では、お客様の製造ラインにあった「予兆検知モデル」を構築することが重要です。どのようなプロセスで構築するのか、そしてどう活用するのか、その概要をご紹介しましょう。※不良予兆検知の場合
まず最初のステップは製造データの可視化です。
予兆検知モデルは製造データによって異なります。ある工場用にチューニングされた予兆検知モデルが他の工場では使えないということがよくあります。これは製造するものや製造方法、工程などによって多くの種類の製造データがあり、データの変動傾向も異なるからです。また工場の場所や環境などの影響を受ける場合もあります。このようなデータの特徴を捉えるための第一歩が可視化です。
当社の経験豊富なアナリスト、データサイエンティストが大量のデータを効果的に可視化します。
製造データをそのまま統計分析や機械学習のインプットにしても精度の高い予兆検知モデルを作ることはできません。製造データを、不良発生の傾向を適切に捉えることができる「特徴量」に変換して予兆検知モデルのインプットにします。
過去の不良発生時のデータを可視化し、簡単な統計分析などを行い特徴量に変換していきます。
例えば、「装置の電圧」そのものではなく、「装置の電圧の微分」のほうが不良発生時の特徴をよくとらえている場合があります。複数のセンサデータが同時に変化すれば問題ないが、一方だけが変化するときに不良が発生する、ということがあります。このような時にはセンサデータ間の相関係数を特徴量として使います。このほかにもタイムウィンドウ内の最大値と最小値の差、ピークとピークの間の時間差、ウェーブレット変換などが特徴量として使われます。このほかにも製造データの傾向によってさまざまな特徴量が考えられますが、特徴量の設計にあたって、製造物や工程に関するお客様の業務知識が役立つことが多くあります。
当社のデータサイエンティストの分析技術とお客様の業務知見を組み合わせることで効率的に特徴量を設計することができます。
特徴量が決まったら、これをインプットとして予兆検知モデルを構築します。
予兆検知モデルには、重回帰モデルやロジットモデル、外れ値検出などの統計手法や、決定木、ニューラルネットワーク、サポートベクターマシン、ランダムフォレスト、ディープラーニングなどの機械学習手法があります。どの手法を用いるかを選ぶ作業を「モデル選択」と言います。「特徴量の設計」と「モデル選択」が予兆検知成功のカギとなります。
ここでは試行錯誤が必要となる場合もあります。特徴量の設計とモデルの選択を行い、過去の製造データで予兆検知の精度の検証を行い、精度が低ければモデルのパラメータの微調整や、場合によっては特徴量の再設計を行う場合もあります。
お客様の業務知見を参考に、当社のデータサイエンティストが過去の事例や経験をもとに精度の高い予兆検知モデルを作り上げていきます。
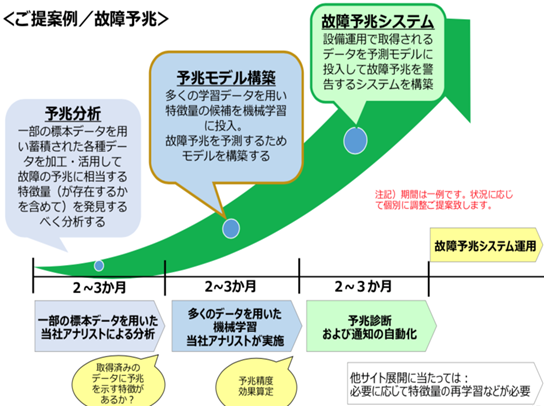
当社のアナリストとデータサイエンティストがお客様データからサンプリングした一部の標本データを用いて予兆分析を行います。
不良や故障の予兆検知に必要なデータがそろっているか、予兆を適切に捉えられる特徴量が設計できそうか、さらに、ある程度の精度で予兆を検知できるかを確認します。
お客様の業務知見を伺いながら、データ理解、データ整合性の確認、欠損値の補填や異常値の削除、複数データソースのデータの結合、そして特徴量の設計、モデル選択などを行います。
データの量や状態によりますが、このステップの期間は2~3か月程度です。
ステップ1では一部のサンプルデータで「味見」を行い予兆分析実現可能性の評価を行います。お客様がお持ちのデータによっては予兆検知に実現に十分なデータ(種類と量)がないため、まずはデータ収集から始めることをご提案する場合もあります。
ステップ2では扱うデータ量を増やして本格的に予兆モデルの構築を行います。
ここでは実運用で必要となる「予兆検知精度」と「汎化(過学習の防止)」の二つの指標を向上させます。
予測精度を向上させるにあたり、誤検知には「正常なのに異常と検知する」という誤りと、「異常なのに正常と検知する」という誤りがあります。この二つの誤りを同時にすべてなくせるのが理想ですが、一方の誤りを減らせば他方の誤りが増えてしまいます。そこで、お客様の実際の業務や運用計画に基づいて、当社のアナリストとデータサイエンティストが適切なバランスとなるように予測精度の向上を行います。
機械学習手法では一般的に学習データでは予測精度が高いが、他のデータでは予測精度が低くなります。ここで、学習データに「過学習」してしまうと、他のデータの予測精度が極端に悪くなることがあります。過去の製造データで学習した予兆検知モデルが、将来の製造データを入力とした場合に予兆検知ができないのでは使い物になりません。このような状況は避ける必要があります。当社のアナリストとデータサイエンティストがクロスバリデーションなどの統計手法を駆使して過学習のない適切な予兆検知モデルを構築します。
「予兆検知モデル」を構築しただけでは、予兆検知するための「数式」が出来上がったにすぎません。日々刻々と発生する製造データをスケジュールに基づいて読み込み、予兆検知モデルに入力し、異常の兆候を監視し続ける予兆検知システムに予兆検知モデルを組み込む必要があります。
予兆検知システムはIoTセンサなどからデータを受け取り、あるいはデータレークから定期的にデータを読み込み、予兆検知モデルで異常予兆の有無を判別し、予兆が発見されれば、必要な情報を担当者にタイムリーに通知します。
「予兆検知システム」を構築することで、予兆検知作業を自動化できます。予兆検知作業とは、設備などから受け取ったデータを元に特徴量を算出し、「予兆検知モデル」にインプットして、異常の可能性を計算する作業に相当します。
日々刻々と変化し発生するデータを、予兆検知したいタイミングにあ合わせて計算する作業を人手で行うことは現実的ではありません。システムによって自動化することで、担当者は他の業務を行いながらも、予兆システムから来るメールなどで異常の兆候を察知し、タイムリーに対応を検討することができます。
なお、一度構築した「予兆検知モデル」がそのままの状態で未来永劫使い続けられるとは限りません。物事の状況や取り巻く環境は、緩やかに(また時として急激に)変化していきます。変化する状況にモデルをアジャストするために、新しく発生したデータを用いて再び分析や学習させるなど、見直しをすることが必要となります。
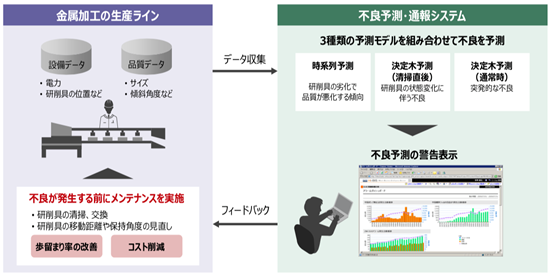


おすすめソリューション
