自動要約システム「CoreExplorer/TS」
発話特有の余計な内容が含まれる
音声認識システムを導入したが、「あ~」「その」などの言いよどみや先頭に”ん”の様な短く意味のないひらがな等、余計な内容が多く含まれていて活用しづらい
ありがとうございます」などの定型文が含まれる
「ありがとうございます」「もしもし」「かしもまりました」などの定型文がいつも含まれていて活用しづらい
認識結果の文が長くCRMなどへの転記工数が増大
認識結果をCRMなどへ転記する業務の場合、文が長いと作業に手間と時間を要して活用しづらい
この3つの課題を解決するのが文章自動要約システム「CoreExplorer/TS」です
CoreExplorer/TSの自動要約は、音声認識のデータから不要な文字列・単語・発話を除去し、その中から文脈を判断し残すべき重要文を抽出します。膨大な発話から不要な発話や、分析に適さない発話を取り除くことで発話の要点を自動的に抽出します。(特許第7288293号)
【 動作の仕組み 】
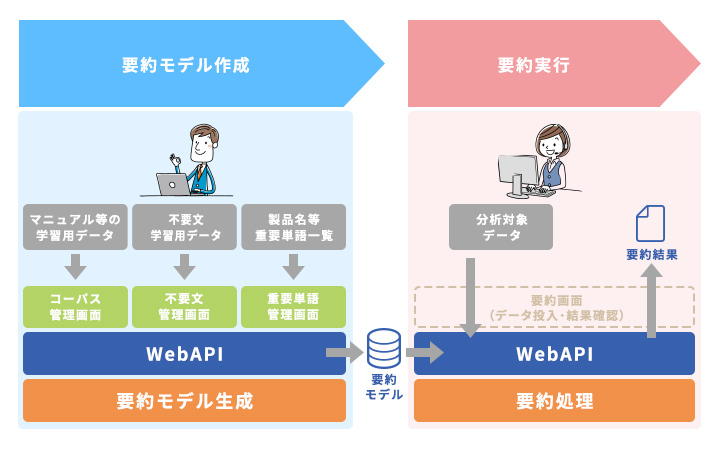
要約に関わる各機能をマイクロサービス化したAPIで提供する仕組みとなります。自社のシステムに組み込んだり、他社製品と連携させたり、バッチ処理で処理をさせるなど、自由な利用方法が可能です。
製品特長を見る 音声認識システムと連携したシステム構成例を見る
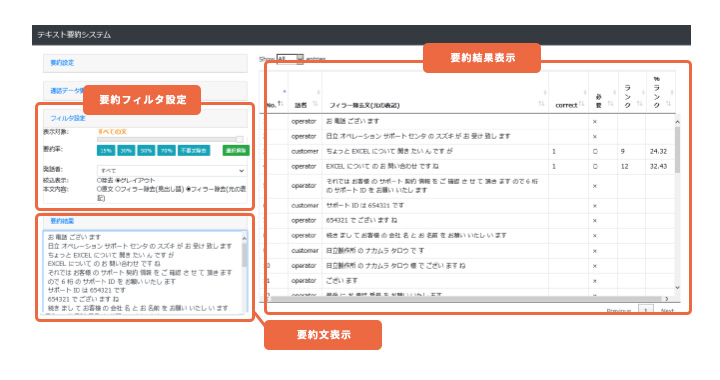
※本画面はサンプル画面になります。画面が必要な場合には用途に合わせた要約画面を個別開発となります。
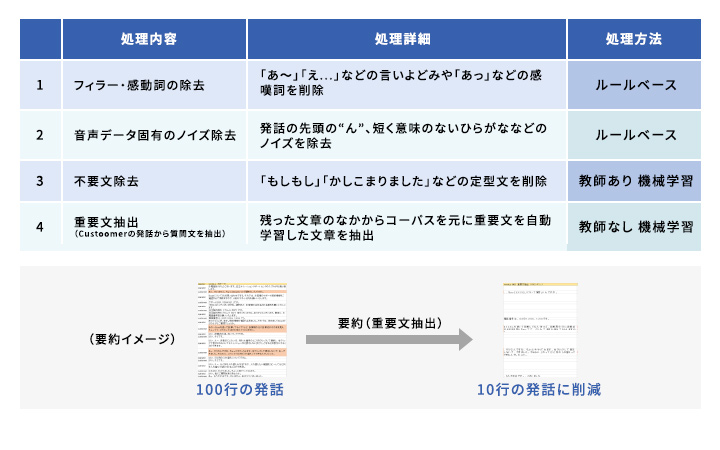
抽出型要約技術により要約文を作成します。音声テキストデータに含まれる言いよどみや定型的な不要文の削除、また機械学習の技術を使い、既存のFAQや過去の問合せ、マニュアルなど業務に関わる情報を取り込むことで重要文を判断し抽出し要約文を作成します。


おすすめソリューション
